X2.5的新程序架构
出自Discuz! 技术文库
Discuz! X2.5新版架构优化说明
主讲人: 张国胜 http://t.qq.com/bilicen
目录 |
主要针对以下6个方面
一.程序底层架构的改进
二.用户输入数据的处理
三.数据库DB层的改进
四.内存级缓存层的优化
五.多服务器分库分布式部署
六.主要性能瓶颈点的优化
程序底层架构
• 要求PHP版本大于5.1,抛弃了对PHP4的支持
• 大量使用了面向对象编程(OOP)
• 实现了程序运程过程中按需加载,按需加载主要是针对类文件
• 对目录名、文件名和类名的要求
类文件存在在/source/class 目录中,类名和文件名相同,一个类一个文件 类名以下划线(_)分隔,第一个下划线之前部分为目录名,没有下划线的类名直接放/source/class/目录下。
产品中个别特殊类由于历史原因无法实现自动加载,需手动处理 include或require
• class_core.php 流程控制的说明
Class_core.php是入口启动文件,主要实现了以下功能:
1、注册autoload方法和异常处理方法;
2、C::t方法的实现;
3、memory的初始化;
4、创建discuz_application实例(discuz_application是原来discuz! X2的discuz_core);
5、简写类的映射:
class C extends core {}
class DB extends discuz_database {}
• function_core.php 减肥之术
function_core.php是系统的核心函数库文件,随着系统功能的丰富,函数库越来越大,慢慢地变成了系统快速启动的负担,为此我们将function_core中的函数按功能拆分到不同的类文件中,实现程序的按需加载; 原有函数名保留不变,做相应类静态方法的映射,兼容产品和插件的用法。
具体做法是在source/class目录增加两个目录,helper和lib source/class/helper目录中的文件为函数的分类集合,类的静态方法,可直接使用不用实例化 source/class/lib目录中的文件为工具类的集合类文件,使用时需实例化
用户输入数据的处理
Discus! X2.5之前版本对$_GET和$_POST的值默认是进行addslashes处理,函数在使用此值时信任外部数据的安全性,但这样处理的弊端是容易生产二次注射的漏洞,为了防止此类漏洞的产生,函数必须不信任任何数据外部数据的安全性,为此我们做了以下的处理增强系统安全:
$_GET和$_POST的值默认不做addslashes处理;
$_GET为$_GET和$_POST数组的合并,代码中统一使用$_GET取值;
$_G['gp_xx']的写法默认不再支持,config.php中有兼容开关;
$_config['input']['compatible'] = 1;// $_GET|$_POST的兼容处理,0为关闭,
1为开启;开启后即可使用$_G['gp_xx'](xx为变量名,$_GET和$_POST集合的所有变量 名),值为已经addslashes()处理过,兼容插件;
数据库DB层
• 原DB类的改进
Discuz! X2.5新版对数据库DB层进行了功能和安全方面的加强:
1、addslashes的处理
insert(),update(),delete()方法对传入其的数组形式的参数进行安全处理:intval或addslashes,字符串形式的参数将不处理,请注意
2、新添加的方法fetch_all($sql),order(), limit(),field()等方法,其中fetch_all方法以数组方式返回查询多条记录数据,且可以设置数据的KEY值使用某字段值
3、SQL语句format的支持
例:查询10个用户uid大于100的用户数据,以uid为返回结果数组的key
$arr = DB::fetch_all(‘SELECT * FROM %t WHERE uid>%d LIMIT %d’, array(‘common_member’, ‘100’, ‘10’), ‘uid’);
支持的fomat有:
| %t | DB::table() |
| %d | intval() |
| %s | addslashes() |
| %n | in IN (1,2,3) |
| %f | sprintf('%f', $var) |
| %i | 直接使用不进行处理 |
4、返回值的处理
在非UNBUFFERED的情况下:
INSERT SQL语句返回insert_id()
UPDATE和DELETE SQL语句返回affected_rows()
• 新增数据层:数据层的规范和约定
• 一个数据表一个class文件,以table_加上不带前缀的表名命名,尽量不操作其它表;
例:source/class/table/table_common_member.php
• 不能使用$_G、$POST、$GET等全局变量;
• 关联查询(JOIN)尽量拆分为单条查询,不能拆分的放入主表的类中;
• 方法名以下划线分隔,全部为小写,全部为单数,直接返回结果,保留关键字:
on、get、set, 方法参数不能以数组的形式传入,数据可以;
• 除数据表文件以外,其它文件禁止出现SQL语句;
• 查询结果返回一行记录方法名使用fetch开头,返回多行记录方法名使用fetch_all
开头,查询中使用SQL语句count函数返回一个数值的使用count开头;
• 方法名中by后面的是以下划线(_)分隔的表字段名,不要使用复数型,例如:
fetch_all_by_uid()而不是fetch_all_by_uids();
• 方法名需去掉表名,如:common_member表类方法
fetch_member_by_username应命名为fetch_by_username;
• 数据表类继承discuz_table基类,基类实现CURD操作,fetch方法实现了根据一个主键 值得到一行记录、fetch_all方法实现了根据一组主键值得到多行记录(二维数据,主 键值为 key)、count方法返回了表的总记录数据;
• 如果表是无主键或是关联主键,则基类中的CURD将不能使用,需自己在相应的表类中实现, 同时将$this->_pk设置为空;
• DB层封装的函数实现了addslashes,个别直接写sql语句的需主意addslashes;
• 使用C::t('tablename')->method();调用;
• C::t插件调用方式
表名:mytablename
目录:source/plugin/mypluginid/table/table_mytablename.php
类名:table_mytablename
用法:C::t('#mypluginid#mytablename')->method();
内存级缓存层
缓存层的引入是为了解决MYSQL自身对高并发处理的性能瓶颈,目前产品缓存层采用主流的Key-Value对形式,内存级的缓存产品很多,支持的内存优化接口有 Memcache、eAccelerator、Alternative PHP Cache(APC)、Xcache、Redis 五种,优化系统将会依据当前服务器环境依次选用接口,单服务器环境中推荐使用APC,多服务器环境中推荐使用Redis或Memcache。
数据层是以表为单位的类文件,所有表类都继承discuz_table基类,基类实现缓存操 作的相关函数;理论上所有的数据表均可以缓存,目前产品在六个压力大的数据表内置开启了缓存 机制:用户相关表、回帖、主题、主题和专辑关系、淘贴专辑、用户关注关系
•用户相关表
缓存表:'common_member', 'count', 'status','profile', 'field_home', 'field_forum';
UID为缓存KEY;
表数据更新时缓存数据会同步更新;
•回帖
以TID为单位,缓存第一页的post数据;
表数据更新时缓存数据会同步更新;
•主题
TID为缓存KEY;
表数据更新时缓存数据会同步更新;
版块列表默认参数第一页时以 forumdisplay_FID 为缓存KEY,缓存时间内数据不更新;
•主题和专辑关系
以TID为单位,此TID的专辑ID集合,表数据更新时缓存数据会同步更新;
•淘贴专辑
以TID为单位,此TID的专辑集合,缓存时间内数据不更新;
•用户关注关系
以UID为单位,此UID关注用户的关系数据,缓存时间内数据不更新;
内存级缓存层实现细节
• discuz_table基类中缓存机制的实现:
/** * @var string 缓存主键名前缀,为空时表示此表不支持缓存 */ protected $_pre_cache_key; /** * @var string 缓存时间,以秒为单位,0表示永久或相关配置文件中的默认值 */ protected $_cache_ttl;
• discuz_table基类中缓存机制的方法:
//缓存一个变量到缓存中,如果 KEY已经在则会被覆盖为新值
store_cache($id, $data, $cache_ttl = null, $pre_cache_key = null)
//获取指定KEY的缓存数据
fetch_cache($ids, $pre_cache_key = null)
//清除指定KEY的缓存
clear_cache($ids, $pre_cache_key = null)
//更新一个已经存在的KEY,只更新修改的字段
update_cache($id, $data, $cache_ttl = null, $pre_cache_key = null)
//批量更新缓存,只更新已经存在KEY的指定修改的字段
update_batch_cache($ids, $data, $cache_ttl = null, $pre_cache_key = null)
//重置已经存在的KEY的值
reset_cache($ids, $pre_cache_key = null)
//累加缓存数据中某字段的值
increase_cache($ids, $data, $cache_ttl = null, $pre_cache_key = null)
多服务器分库分布式部署
分布部署
Discuz! X系统功能丰富,数据表多达200多个,在实际生产环境中对各种功能的深度使用各不一样,导致每个数据表都有可能承受高并发的访问压力,当出现这种情况时,需要将负载大的数据表及其相关数据表单独部署,以增强系统的负载能力。
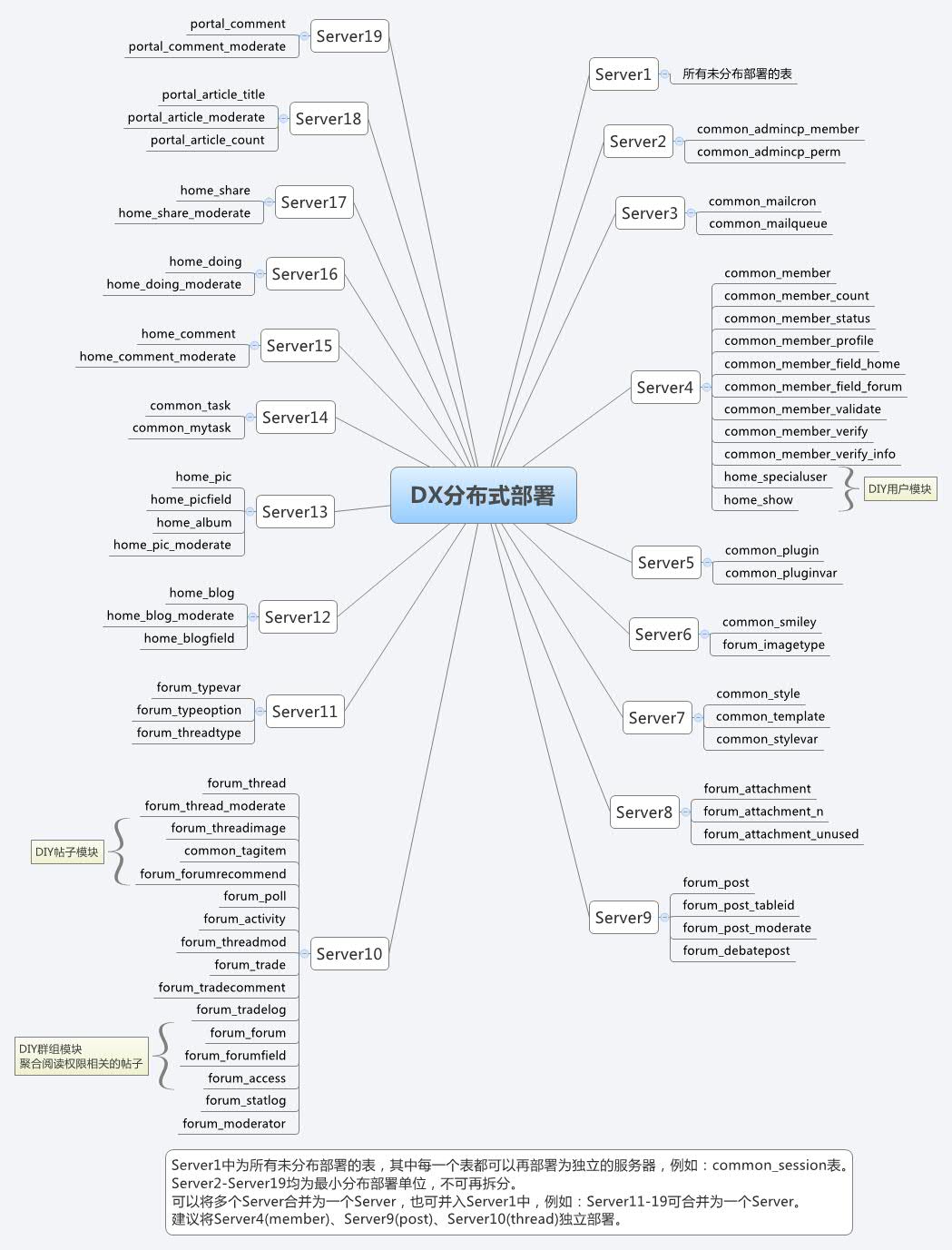
Discuz! X2.5此次改进理论上支持以表为单位的数据库分布式部署,部分无法独立部署的表将与其相关表被合并为最小部署单位。以下图为例:
Media:DX分布式部署.jpg
{kind=link}
• Server1中为所有未分布部署的表,其中每一个表都可以再部署为独立的服务器,例如: common_session表;
• Server2-Server19均为最小分布部署单位,不可再拆分;
• 可以将多个Server合并为一个Server,也可并入Server1中,例如:Server11-19可合并为一个 Server;
• 建议将Server4(member)、Server9(post)、Server10(thread)独立部署
配置文件(config_global.php)
// ---------------------------- CONFIG DB ----------------------------- //
$_config['db']['1']['dbhost'] = 'localhost';
$_config['db']['1']['dbuser'] = 'root';
$_config['db']['1']['dbpw'] = 'root';
$_config['db']['1']['dbcharset'] = 'gbk';
$_config['db']['1']['pconnect'] = '0';
$_config['db']['1']['dbname'] = 'superbase';
$_config['db']['1']['tablepre'] = 'pre_';
$_config['db']['common']['slave_except_table'] = ;
$_config['db']['2']['dbhost'] = '2.cn';
$_config['db']['2']['dbuser'] = 'root';
$_config['db']['2']['dbpw'] = 'root';
$_config['db']['2']['dbcharset'] = 'gbk';
$_config['db']['2']['pconnect'] = '0';
$_config['db']['2']['dbname'] = 'superbase_2';
$_config['db']['2']['tablepre'] = 'pre_';
...
$_config['db']['19']['dbhost'] = ‘19.cn';
$_config['db']['19']['dbuser'] = 'root';
$_config['db']['19 ']['dbpw'] = 'root';
$_config['db']['19 ']['dbcharset'] = 'gbk';
$_config['db']['19 ']['pconnect'] = '0';
$_config['db']['19 ']['dbname'] = 'superbase_19';
$_config['db']['19 ']['tablepre'] = 'pre_';
// ---------------------------- 配置map ----------------------------- //
$_config['db']['map']['common_admincp_perm'] = '2';
$_config['db']['map']['common_admincp_member'] = '2';
$_config['db']['map']['common_mailqueue'] = '3';
$_config['db']['map']['common_mailcron'] = '3';
$_config['db']['map']['common_member_verify_info'] = '4';
$_config['db']['map']['common_member_verify'] = '4';
$_config['db']['map']['common_member_validate'] = '4';
...
$_config['db']['map']['portal_article_moderate'] = '18';
$_config['db']['map']['portal_article_title'] = '18';
$_config['db']['map']['portal_article_count'] = '18';
$_config['db']['map']['portal_comment_moderate'] = '19';
$_config['db']['map']['portal_comment'] = '19';
没有进行map配置的数据表将默认读写$_config['db']['1']的链接
主要性能瓶颈点的优化
• member表优化
• Post表优化
• Thread表点击数优化
• DIY模块数据更新优化
• 帖子点评和评分功能的优化
• member表优化
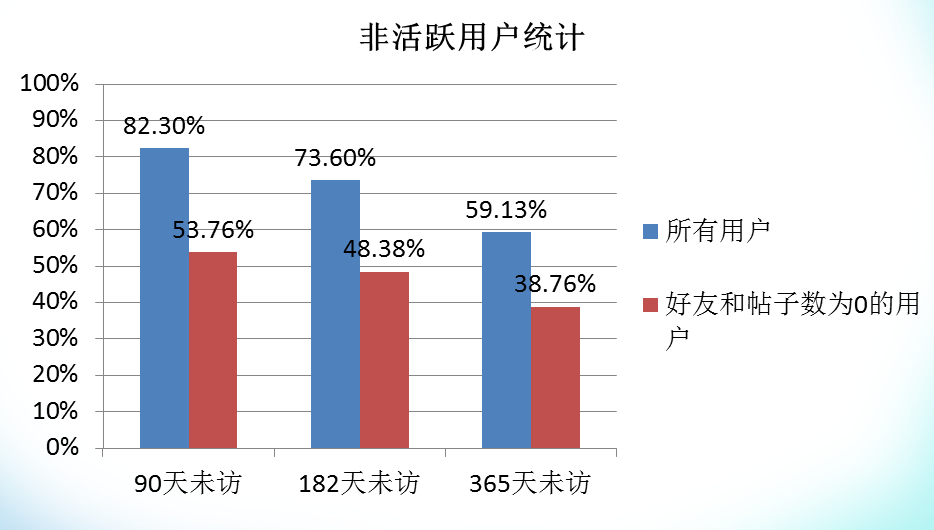
当一个数据表的数据量越来越大时,关于这个表的查询和更新操作就会变量越来越慢,为了提高数据库表的响应速度,应该时刻保持表数据的精简。那么如何既不影响正常功能又能保证表数据的精简?我们在十几个注册会员数从几十万到几百万不等的网站进行了一项非活跃用户数的统计,统计结果如下图:
{kind=link}
统计结果显示非活跃用户数和活跃用户数的比例趋近于82规则,即非活跃用户数占大部分,因此只要我们将非活跃用户进行存档即可大大减少用户表的数据量,提高访问速度。
存档的标准是:
90天之内无访问且帖子数小于5,估算可优化60%以上用户
程序处理
a、用户在回访时将数据从存档表中转移到主表
b、单用户默认均不兼容处理
加为好友、打招呼、发短信将提示用户不存在或被冻结
用户空间、查看用户资料页可正常显示
c、多用户操作默认兼容处理
好友列表,帖子查看页可正常显示
d、后台用户管理时需要选表操作
升级转换:
平均处理1000个用户需要20分钟
• post表的优化
问题:
高楼贴的性能问题 limit 187460, 20
方法:
增加position字段记录楼层,修改主键为:PRIMARY KEY (tid, `position`)联合主键,其中position 为auto_increment;
pid字段保留,仍然是auto_increment(单独的一个表),保持唯一,其值在一个单独的表中记录, 保留此字段的主要目的是可以让原程序的基本不用做修改;
使用方法:
SELECT * FROM pre_forum_post WHERE tid=424 AND position>=$start AND position<$end ORDER BY position;
抢楼贴和普通的盖楼贴机制统一;
兼容处理
悬赏 商品 辩论保留原来的机制处理;
删除和审核保留原来的机制,页面显示此楼层被删除或审核中;
升级转换
本机测试,2000万数据,1小时30分
• 点击数优化
问题:
频繁的写表操作导致锁表
方法:
增加forum_threadaddviews表,记录每一个TID的增量点击数;
查看帖子时,如果增量点击数到100,则使用进程锁将数据更新到thread表并更新增量点击数为0;
回贴时将增量点击数和回复数一起更新到thread表,并更新增量点击数为0;
执行计划任务:每天3点,5分钟一次,一次取500条数据更新到thread表, 并删除此500条数据,以减少forum_threadaddviews表的大小;
兼容处理
版块列表页和帖子查看页中,将增量点击数查询出来并累加到主题的views;
• DIY模块更新数据优化
问题
由于模块聚合数据的灵活性导致SQL语句的条件复杂且不使用索引,
不使用索引的结果就是MYSQL对数据表的全表扫描,
对大表的全表扫描将使网站的整体性能急剧下降
方法:
在查询语句的WHERE条件中增加 id > max(id) - $maxnum;
最多扫描$maxnum行数据,产品后台可设置此值,最大是65535;
主题、文章、日志模块中添加此功能;
• 帖子点评和评分功能的优化
问题:
DB::query("SELECT * FROM ".DB::table('forum_postcomment')." WHERE pid IN (".$_G[forum_cachepid'].') ORDER BY dateline DESC');
DB::query("SELECT * FROM ".DB::table('forum_ratelog')." WHERE pid IN (".$_G[forum_cachepid'].") ORDER BY dateline DESC");
方法:
增加forum_postcache表,记录每一个PID的点评列表和评分列表的结果;
查看帖子时生成缓存,点评和评分时删除缓存
执行计划任务:每天删除前一天的数据,以减少forum_postcache表的大小;